
概要
「人の声のembeddingが得られれば、声の近い遠いが定量的にわかるのでは」みたいなアイデアからうまれた「声の地図」を作るWebアプリ
技育展2023決勝進出作品
https://vvwiki.vercel.app/

やってること
Vtuberの配信URLから配信音源をダウンロード → embedding → PCAして画面に表示 みたいなことをしてます
サーバー側のソースコード
speaker-embedding
ある音声が誰の声かを当てるようなニューラルネットワークを作った時、その中間層には声の特徴をよく表す数値が入っているのではないか というアプローチで、声のembeddingを取得するモデルが作れます。
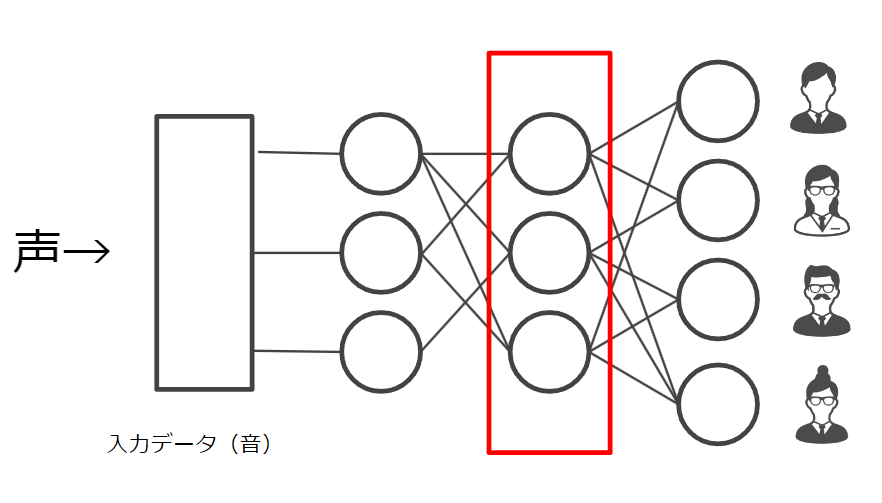 当初は自前で作っていましたが、最終的にはhugging face の pyannote/embeddingさんを使うことにしました。
当初は自前で作っていましたが、最終的にはhugging face の pyannote/embeddingさんを使うことにしました。
音源確保
YouTubeのURLからyoutube-dlpを用いて音声をダウンロードし、良い感じに切り取ってembeddingに突っ込み、最終的に特徴量ベクトルを得る という一連のパイプラインを敷きました。
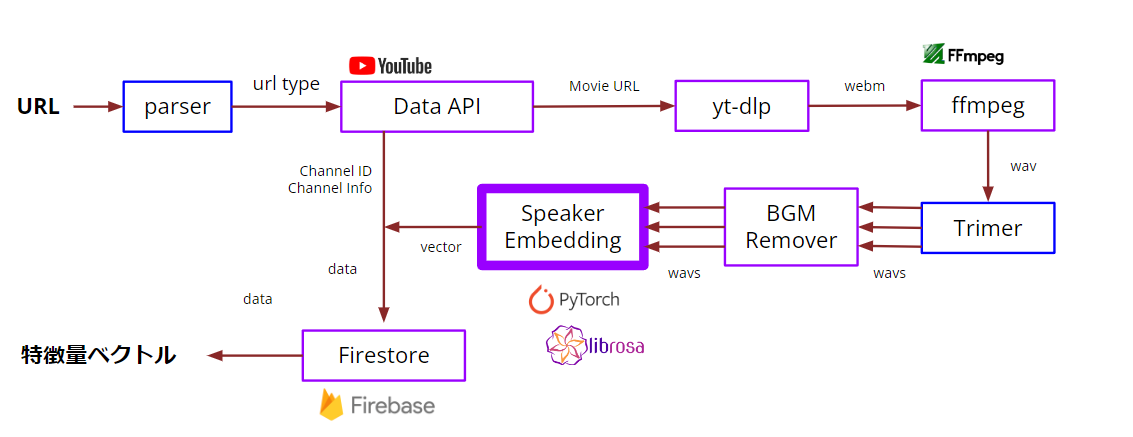 やることやってるだけなので技術的な面白みはあまりないですが、やることが多いせいで3日間のハッカソンのうち丸1日がこれにつぶれました。
やることやってるだけなので技術的な面白みはあまりないですが、やることが多いせいで3日間のハッカソンのうち丸1日がこれにつぶれました。
座標圧縮と表示
得られたembeddingは多次元ベクトルなので上手いことディスプレイに落とし込む必要があります。
いくつか考えましたが、最終的にはPCAで3次元に落としこみ極座標系に変換したのち、, 成分を地球儀の座標で、成分を色で表すことで、地球儀を回す感覚で「声を探せる」体験の実現を試みました。ある程度はそれっぽい分布になる一方で、(メルカトル図法の地図と同じく)北極側がスカスカになってしまうという問題点があり、改良の必要がありそうです。
フロントエンド
クライアント側のソースコード
Next.js + React + (申し訳程度の) tailwind.css で作りました。機能自体は非常にシンプルなので、コード量としては大したことはないです。